Необходимые знания
Мы старались сделать компонент "Парсер контента" простым и доступным каждому человеку, независимо от уровня его технических познаний. Именно поэтому мы не включили в состав компонента многие механизмы, которые были бы сложны для понимания большинством пользователей. Напирмер структуры DOM и регулярные выражения. Пользоваться компонентом сможет каждый, кто в состоянии просмотреть исходный код HTML-страницы и найти в нем интересующий его участок кода. При этом не требуется ни знания самого HTML, ни других специфических навыков. Давайте рассмотрим на примере, как именно проходит работа с парсером.
Шаг первый
Допустим мы хотим настроить публикацию новостей, посвященных теме "Наука и техника", с сайта N(или определенного раздела этого сайта). Для этого нам нужно перейти в интересующий нас раздел сайта, найти на странице блок с анонсами тех материалов, которые нам интересны. Допустим, итересующий нас фрагмент выглядит так:

Ка видно на картинке, данная страница является лентой статей из раздела "Техника" сайта N. Все публикации, касающиеся данной темы публикуются именно здесь. Изучим HTML-код данной страницы и найдем в нем блок с интересующими нас анонсами:
<div id="main" class="grid_12"> <div class="pathway"><a href="/" class="pathwaylink">Главная</a> → <a href="/poznavatelno" class="pathwaylink">Познавательно</a> → <a href="/poznavatelno/tehnika" class="pathwaylink">Наука и техника</a> </div> <div class="component"> <h5 class="p1">Механизмы и транспорт <div class="con_rss_icon"> <a href="/rss/content/27/feed.rss" title="RSS-лента"><img src="/templates/_solo_/images/icons/rss.png" alt="RSS-лента" border="0"></a> </div> </h5> <table border="0" cellspacing="2" width="100%"> <tbody> <tr> <td valign="top" width=""><div class="con_title"> <h5 class="p1"><a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/parovik-hhi-veka.html">Паровик ХХI века</a></h5> </div> <div class="con_desc"> <div class="con_image"> <img src="/images/photos/small/article439.jpg" alt="Паровик ХХI века" border="0" height="85"> </div> <div>У паровой машины - славное прошлое. В 2010 году исполнилось 245 лет со дня первого пуска стационарной паровой машины по проекту русского механика И.И. Ползунова. А 75 лет назад была построена первая советская высокооборотная паровая машина, которая могла... <div style="height:20px; position: absolute; bottom: 0; right:0;"> 30 марта 2015 - <a title="" class="null utip" rel="deniss" href="/users/deniss" style="color: rgb(102, 102, 102);">Денис Коринцев</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/parovik-hhi-veka.html" title="Подробнее">Подробнее</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/parovik-hhi-veka.html#c" title="Комментарии">0 комментариев</a> | 1209 просмотров </div> </div> </div></td> </tr> <tr> <td valign="top" width=""><div class="con_title"> <h5 class="p1"><a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/kak-avtobus-stanovilsja-avtobusom-a-gruz.html">Как автобус становился автобусом, а грузовик - грузовиком...</a></h5> </div> <div class="con_desc"> <div class="con_image"> <img src="/images/photos/small/article408.jpg" alt="Как автобус становился автобусом, а грузовик - грузовиком..." border="0" height="85"> </div> <div>Мало кто не знает, что первый в мире автомобиль появился на свет в 1886 году. Точнее, почти одновременно появились сразу два первых автомобиля — один построил Карл Бенц, другой Готлиб Даймлер. Многие опять-таки знают, что оба автомобиля были легковыми, для двух-трёх... <div style="height:20px; position: absolute; bottom: 0; right:0;"> 26 марта 2015 - <a class="null utip" rel="sergas" href="/users/sergas" style="color:#666">Сергей Коваленко</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/kak-avtobus-stanovilsja-avtobusom-a-gruz.html" title="Подробнее">Подробнее</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/kak-avtobus-stanovilsja-avtobusom-a-gruz.html#c" title="Комментарии">0 комментариев</a> | 537 просмотров <br> </div> </div> </div></td> </tr> ... <tr> <td valign="top" width=""><div class="con_title"> <h5 class="p1"><a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/vyzhimat-vodu-iz-vozduha.html">Выжимать воду. Из воздуха!</a></h5> </div> <div class="con_desc"> <div class="con_image"> <img src="/images/photos/small/article218.jpg" alt="Выжимать воду. Из воздуха!" border="0" height="85"> </div> <div>Это не магия, а достижение инженерной мысли! Прибор — обладатель премии Джеймса Дайсона в 2011 году — извлекает воду из воздуха. Airdrop — недорогое и простое в установке устройство с автономным питанием, помогающее решать проблемы с выращиванием урожая в засушливых... <div style="height:20px; position: absolute; bottom: 0; right:0;"> 2 мая 2014 - <a class="null utip" rel="admin" href="/users/admin" style="color:#666">Александр Малинский</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/vyzhimat-vodu-iz-vozduha.html" title="Подробнее">Подробнее</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/vyzhimat-vodu-iz-vozduha.html#c" title="Комментарии">0 комментариев</a> | 714 просмотров </div> </div> </div></td> </tr> <tr> <td valign="top" width=""><div class="con_title"> <h5 class="p1"><a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/banany-kak-osnova-avtomobilestroenija.html">Бананы как основа автомобилестроения</a></h5> </div> <div class="con_desc"> <div class="con_image"> <img src="/images/photos/small/article210.jpg" alt="Бананы как основа автомобилестроения" border="0" height="85"> </div> <div>Исследователи из университета бразильского города Сан-Паулу обнаружили, что полученные особым способом из волокон банановых и ананасовых пальм наночастицы способны сделать прочнее пластмассы, применяемые при изготовлении корпусов автомобилей. Более того, из такого... <div style="height:20px; position: absolute; bottom: 0; right:0;"> 25 апреля 2014 - <a class="null utip" rel="vladis" href="/users/vladis" style="color:#666">Владимир Вишневский</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/banany-kak-osnova-avtomobilestroenija.html" title="Подробнее">Подробнее</a> | <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/banany-kak-osnova-avtomobilestroenija.html#c" title="Комментарии">0 комментариев</a> | 471 просмотр <br> </div> </div> </div></td> </tr> </tbody> </table> <div class="pagebar"><span class="pagebar_title"><strong>Страницы: </strong></span><span class="pagebar_current">1</span> <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/page-2" class="pagebar_page">2</a> <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/page-2" class="pagebar_page">Следующая</a> <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/page-2" class="pagebar_page">Последняя</a> </div> <script type="text/javascript" src="/plugins/p_usertip/p_usertip.js"></script><script type="text/javascript" src="/plugins/p_usertip/cluetip/jquery.cluetip.js"></script>
Как мы видим, весь блок с интересующими нас анонсами публикаций находится между <div id="main" class="grid_12"> и <div class="pagebar">. В этом фрагменте кода находятся следующие ссылки:
/poznavatelno /poznavatelno/tehnika /rss/content/27/feed.rss /poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/parovik-hhi-veka.html /users/deniss /poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/kak-avtobus-stanovilsja-avtobusom-a-gruz.html /users/sergas /poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/vyzhimat-vodu-iz-vozduha.html
и т.д. При этом практический интерес для нас представляют только 3 ссылки:
/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/parovik-hhi-veka.html /poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/kak-avtobus-stanovilsja-avtobusom-a-gruz.html /poznavatelno/nauka-i-tehnika/mehanizmy-i-transport/vyzhimat-vodu-iz-vozduha.html
Эти ссылки ведут на страницы с полным текстом интересующих нас публикаций, остальные ссылки нам попросту не нужны. Причем нам даже неважен формат этих ссылок, парсер сам заменит относительные пути на абсолютные и исправит другие ошибки в URL.
Что можно сделать, чтобы получить список только нужных нам ссылок? Правильно, подвергнуть этот список фильтрации. В нашем случае все ссылки на страницы с публикациями имеют окончание .html, в то время как ссылки типа
/poznavatelno /poznavatelno/tehnika /rss/content/27/feed.rss /users/deniss
такого окончания не имеют. Просто введем в поле "Белый список" фразу ".html" и получим нужный нам результат. Парсер выберет ссылки, содержащие фразу ".html" и отбросит все остальные. У нас должна получиться примерно такая картина:
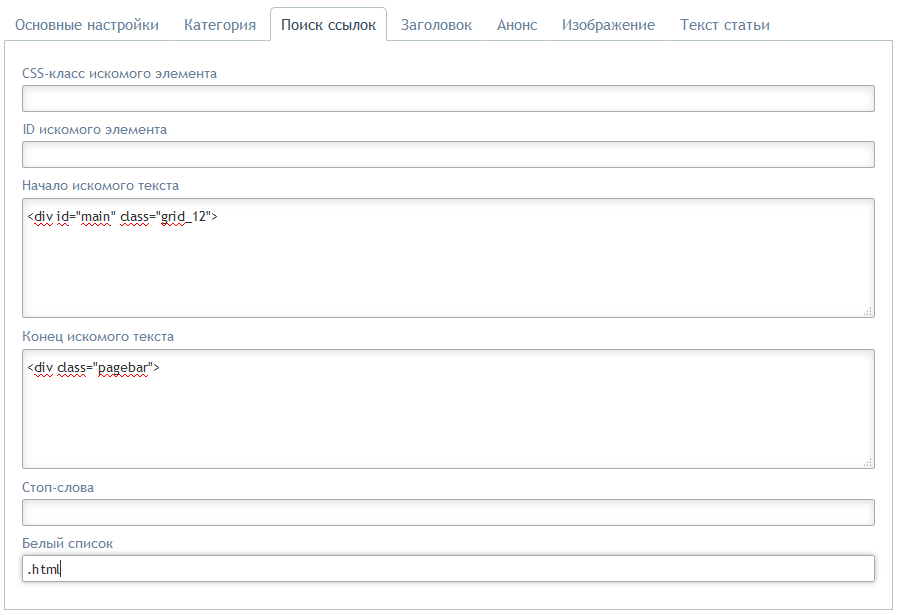
Таким образом мы объяснили парсеру, по каким страницам он должен ходить в поисках интересующего нас контента.
Шаг второй
Следующим делом мы должны научить парсер правильно обрабатывать страницу с полным текстом публикации чтобы парсер мог выбрать из HTML-кода статьи заголовок статьи, картинку к публикации, текст публикации и т.д. Звучит сложно и запутанно, однако на практике все делается очень просто. Итак, начнем.
Откроем любую ссылку из полученного нами в шаге 1 списка ссылок и изучим HTML-код страницы. В нашем случае мы увидим вот такой HTML-код:
<div id="main" class="grid_12"> <div class="pathway"><a href="/" class="pathwaylink">Главная</a> → <a href="/poznavatelno" class="pathwaylink">Познавательно</a> → <a href="/poznavatelno/tehnika" class="pathwaylink">Наука и техника</a> → <a href="/poznavatelno/nauka-i-tehnika/mehanizmy-i-transport" class="pathwaylink">Механизмы и транспорт</a> </div> <div style="opacity: 1;" class="component"> <h1 class="p1">Паровик ХХI века</h1> <div class="con_text"> <img src="/images/photos/medium/article439.jpg" alt="article439.jpg"> <div>У паровой машины - славное прошлое. В 2010 году исполнилось 245 лет со дня первого пуска стационарной паровой машины по проекту русского механика И.И. Ползунова. А 75 лет назад была построена первая советская высокооборотная паровая машина, которая могла «разгоняться» до 1800 об/мин! Стоит ли вспоминать об этом в наш век высоких технологий? Оказывается, да. Потому что паровые поршневые двигатели вновь могут найти себе применение. </div> ... </div> <div id="con_rating_block"> <table width="100%"><tbody><tr><td style="padding-top:4px;">
где
<h1 class="p1">Паровик ХХI века</h1>
это заголовок новости. Чтобы объяснить парсеру как искать заголовки статей на сайте N укажем в настройках задания следующее:
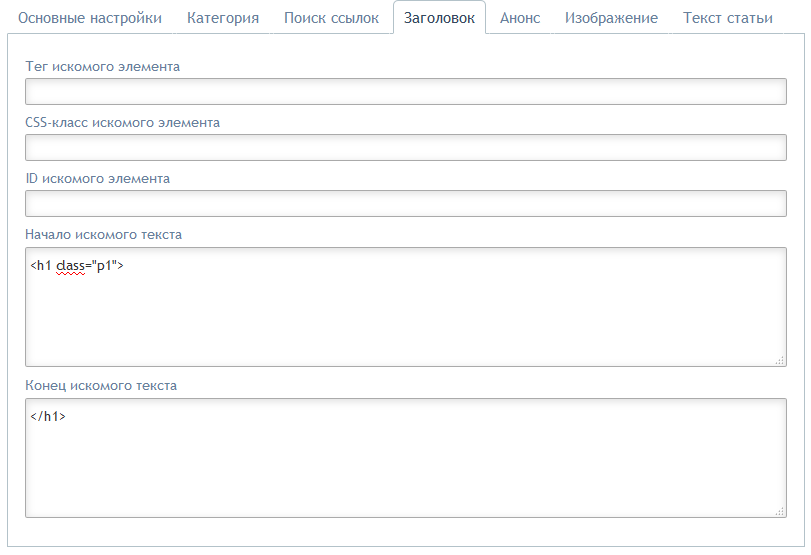
Как видно на рисунке, мы попросили парсер считать заголовком статьи текст, находящийся между тегами <h1 class="p1"> и </h1>.
<img src="/images/photos/medium/article439.jpg" alt="article439.jpg">
это изображение к статье. Как видно из кода изображение находится между тегами <div class="con_text"> и <div>. Просто указываем это в настройках парсера, все остальное за нас он сделает сам - удалит лишний HTML, получит URL картинки, загрузит ее на ваш сервер и создаст превью указанных вами размеров(micro, small, normal, big, original).
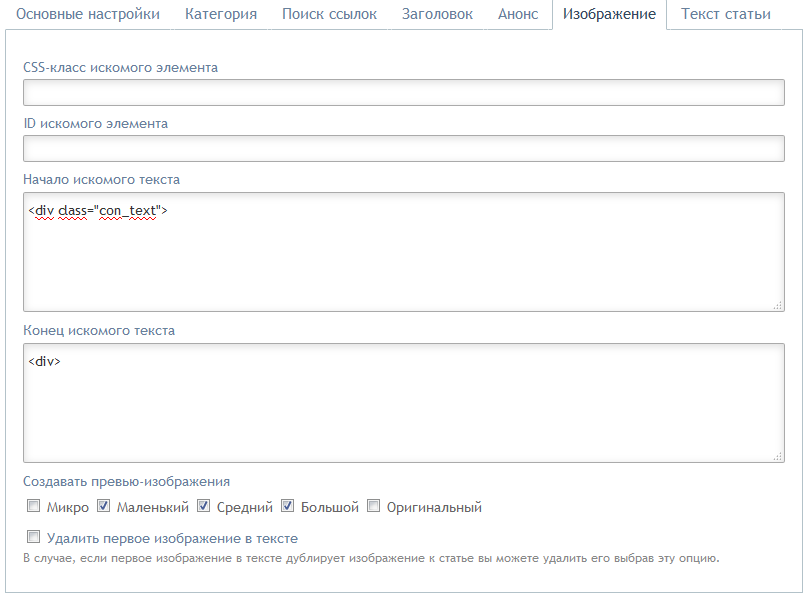
Как видно на картинке мы попросили парсер искать изображение к статье между тегами <div class="con_text"> и <div> и указали, что парсер должен создавать для изображений к публикациям превью размеров small, normal, big.
Итоги
Мы рассмотрели настроку задания для получения публикаций с сайта N - поиск ссылок на интересующие нас публикации, выбор заголовка статьи и изображения к статье. Если все, что написанно выше было вам понятно, то вы без труда сможете настраивать собственные задания самостоятельно. Настройка получения краткого и полного текста статьи полностью аналогична, поэтому описывать ее здесь мы не будем. Однажды настроив задание для сайта N мы можем получать публикации с этого сайта выполняя созданное задание вручную или доверив его запуск CRON-у, полностью автоматизировав публикацию контента на сайте.
Комментарии