Заголовок статьи
После того, как мы закончили с поиском ссылок пора заняться определением правил, по которым парсер должен будет находить интересующий нас контент на целевых страницах. Для этого вам необходимо открыть любую страницу со статьей, ссылка на которую содержится в найденном парсером списке ссылок и изучить фрагмент HTML-кода, содержащий заголовок статьи. Это может быть абсолютно любая структкра HTML-тегов, начиная от простейшего <h2>заголовок</h2> до самых хитроумных конструкций, однако для нас это практически ничего не меняет.
Для поиска заголовка вам доступны поиск по тегу, CSS-классу, ID, а также наш основной инструмент - поля "Начало искомого текста" и "Конец искомого текста". Рассмотрим все возможные варианты:
Поиск по тегу
Если вы, изучив исходный код страницы пришли к выводу, что тег, содержащий нужный нам заголовок уникален, то самый простой способ объяснить парсеру, что от него требуется, это воспользоваться полем "Тег искомого элемента". Просто введите в это поле название тега и парсер в ходе выполнения задания будет брать заголовок из тега, указанного вами в этой строке. Но перед этим убедитесь, что данный тег размещен на странице в единственном числе и, в случае, если таких тегов несколько, находится в коде страницы первым. Например, мы открываем исходный код страницы и видим следующее:
<body leftmargin="10" topmargin="10" rightmargin="10" marginheight="10" marginwidth="10"> <h1>Фотографии, сделанные туристами-иностранцами в Советском Союзе в 1977 году</h1> Автор: <em>yriczp2011, 4.10.2016 22:20</em> <br><br>
Убедившись, что на странице больше нет тегов H1, вписываем "h1" в поле "Тег искомого элемента":

Результатом работы парсера будет:
Фотографии, сделанные туристами-иностранцами в Советском Союзе в 1977 году
Получение заголовка настроено и можно переходить к настройке следующего поля.
Поиск по CSS-классу или ID
Поиск по CSS-классу и ID полностью аналогичен поиску по тегу, разве что с тем отличием, что мы получим содержимое элемента с указанным ID или CSS-классом. Например, если заголовок статьи имеет вид:
<body leftmargin="10" topmargin="10" rightmargin="10" marginheight="10" marginwidth="10"> <div id="title">Фотографии, сделанные туристами-иностранцами в Советском Союзе в 1977 году</h1> Автор: <em>yriczp2011, 4.10.2016 22:20</em> <br><br>
или
<body leftmargin="10" topmargin="10" rightmargin="10" marginheight="10" marginwidth="10"> <p class="title">Фотографии, сделанные туристами-иностранцами в Советском Союзе в 1977 году</p> Автор: <em>yriczp2011, 4.10.2016 22:20</em> <br><br>
то, введя класс или ID нужного нам элемента в соответствующее поле, мы получим нужный нам результат:

вернет нам содержимое тега, имеющего CSS-класс "title", а

вернем нам содержимое тега с id="title".
Получение заголовка настроено и можно переходить к настройке следующего поля.
Поиск в коде
В прошлой главе руководства мы уже познакомились с полями "Начало исходного текста" и "Конец исходного текста". Их применение и тут ничем не отличается от применения, описанного в прошлой главе. Для того, чтобы получить заголовок статьи используя эти поля достаточно указать фрагмент кода предшевствующий заголовку и фрагмент кода, следующий после заголовка. Например,
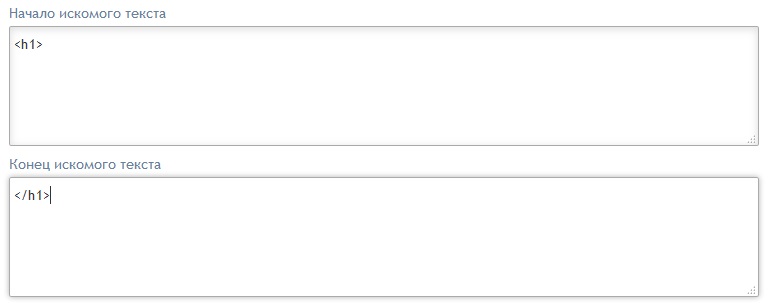
вернет нам все тот же заголовок h1, однако смысла в таком использовании данных полей нет. Ведь эта задача гораздо элегантнее решается при помощи поля "Тег искомого элемента". Однако есть ряд ситуаций, где данный тип поиска окажется незаменим. Давайте рассмотрим следующий фрагмент кода:
<div class="field ft_caption f_title"> <div class="value"> <a href="/articles/146-konec-neftegazovoi-epohi-blizok.html">Конец нефтегазовой эпохи близок</a> </div> </div> <div class="field ft_html f_teaser"> <div class="value"> Глава Сбербанка России Герман Греф спрогнозировал, что сырьевые запасы РФ могут закончиться уже к 2028-2030 годам. По мнению Грефа, даже если он ошибся с точными сроками, повторения суперсырьевого цикла, который наблюдался последний десяток лет, уже ... </div> </div> </div> <div class="info_bar"> <div class="bar_item bi_rating"> <div class="rating_widget" id="rating-articles-146" data-target-controller="content" data-target-subject="articles" data-target-id="146" data-info-url="/rating/info">
Наверное многие уже обратили внимание, что это стандартный код вывода статей из второй ветки Инстанта. Как мы видим из кода, здесь нет ни специфичных тегов типа h1, а сам заголовок содержится внутри тега <div class="value">, коих на странице множество. Именно в таких ситуациях поля "Начало исходного текста" и "Конец исходного текста" придут нам на помощь. Введя в данных полях
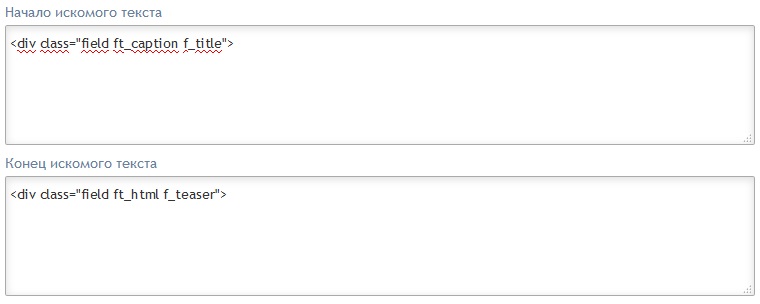
мы получим наш заголовок. Если быть точным, то результатом выполнения будет
<div class="value"> <a href="/articles/146-konec-neftegazovoi-epohi-blizok.html">Конец нефтегазовой эпохи близок</a> </div>
однако после очистки от HTML мы получим наш заголовок в чистом виде. Поскольку сам формат поля "Заголовок" не предполагает наличия в нем HTML-тегов, то данное поле будет очищено парсером от любого HTML-кода автоматически, без нашего участия. Это дает нам возможность получать значения из любых фрагментов кода любой вложенности. Рассмотрим еще один пример:
<div class="c-main-section">
<div class="c-main-section__header">
<div class="c-main-section__title"> Похожие сериалы </div>
<div class="c-main-section__supplimentary"></div>
<div class="c-main-section__actions"></div>
</div>
<div class="c-main-section__body">
<ul class="c-card-list s-card-list--five-cols s-card-list--tile">
<li class="c-card-list__item">
<div class="o-card s-card-movie s-card-movie--medium" itemscope="">
<div class="o-card__img-frame">
<div class="o-card__img-limiter">Заточенные кепки / Острые козырьки
<div class="o-card__img-shifter"> <img class="o-card__img" src="/uploads/posts/2014-10/1412402172_fe38095c3fa39d2b47041e6c77c7c0f1_220.jpg" >
<div class="o-card__img no-img"></div>
</div>
</div>
</div>
</div>
чтобы получить из данного фрагмента кода заголовок "Заточенные кепки / Острые козырьки" достаточно указать лишь любой уникальный тег, находящийся до заголовка и такой же тег после. И при этом неважно, какое количество HTML-тегов будет находиться между ними. Если ввести
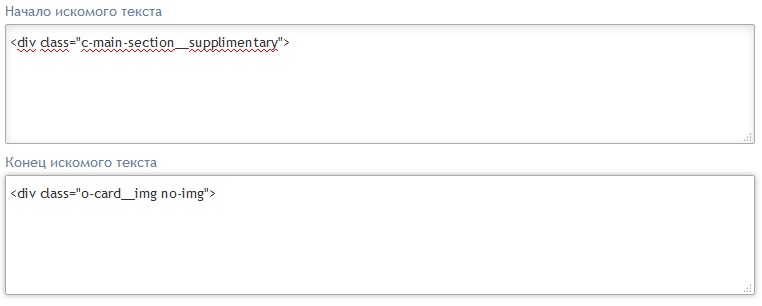
то результатом все равно будет
Заточенные кепки / Острые козырьки
На этом пожалуй и все. Получение заголовка настроено и можно переходить к настройке следующего поля.
Комментарии